
I am a graduate student in the Department of Electrical and Computer Engineering at Carnegie Mellon University, fortunately working with Prof. Greg Ganger in Parallel Data Lab and Prof. Zhihao Jia in Catalyst Group.
My research focuses on exploring ways to enhance scalability, performance, and efficiency of large scale data-centric applications from both systems and algorithms perspective.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Carnegie Mellon UniversityDepartment of Electrical and Computer Engineering
Carnegie Mellon UniversityDepartment of Electrical and Computer Engineering
Master of Science in Electrical and Computer EngineeringJan. 2025 - present -
 University of Wisconsin-MadisonBachelor of Science in Computer ScienceSep. 2022 - Jul. 2024
University of Wisconsin-MadisonBachelor of Science in Computer ScienceSep. 2022 - Jul. 2024 -
 University of WaterlooBachelor of Mathematics in Combinatorics & OptimizationSep. 2020 - Jul. 2022
University of WaterlooBachelor of Mathematics in Combinatorics & OptimizationSep. 2020 - Jul. 2022
Selected Experiences
-
Carnegie Mellon UniversityResearch Staff -> Graduate Student Research AssistantSept. 2024 - present
-
 Microsoft ResearchResearch InternMay 2024 - Aug. 2024
Microsoft ResearchResearch InternMay 2024 - Aug. 2024 -
University of Wisconsin-MadisonUndergraduate Student Research AssistantJan. 2023 - May 2024
-
 GoogleSoftware Engineer InternJan. 2022 - April. 2022
GoogleSoftware Engineer InternJan. 2022 - April. 2022 -
 Ford MotorMedia & USB Infotainment Developer InternSep. 2021 - Dec. 2021
Ford MotorMedia & USB Infotainment Developer InternSep. 2021 - Dec. 2021
Experience Details
My journey began with operating systems internals. I started by working at Ford, where I customized Android system components relevant to multi-media and USB. Later at Google, I contributed to designing a unified customization interface for OEMs to make such modifications more smoothly and securely. After transferring to UW-Madison, I started to focus on systems research.
My systems researches are primarily about bandwidth issues in modern data-intensive applications. At UW-Madison, I worked on ways to make consensus protocols bandwidth-adaptive, advised by Prof. Remzi Arpaci-Dusseau and Prof. Andrea Arpaci-Dusseau. Currently, I’m working with Prof. Greg Ganger at Carnegie Mellon University’s Parallel Data Lab , where I contribute to re-designing IO interfaces in data center file systems to better utilize bandwidth.
Building on this systems foundation, I have also explored problems at the intersection between systems and machine learning.
On the machine learning side, I was working on improving LLMs’ planning and tool use abilities in software engineering and infra ops domains at Microsoft Research, fortunately supervised by Dr. Xuan Feng and Dr. Sameh Elnikety.
Currently, I’m also collaborating with Prof. Zhihao Jia at Carnegie Mellon University’s Catalyst Group about improving LLM' inference with sparse attention. We are taking an end-to-end approach -- optimize LLMs’ inference from model structure to kernel implementations.
News
Selected Publications (view all )
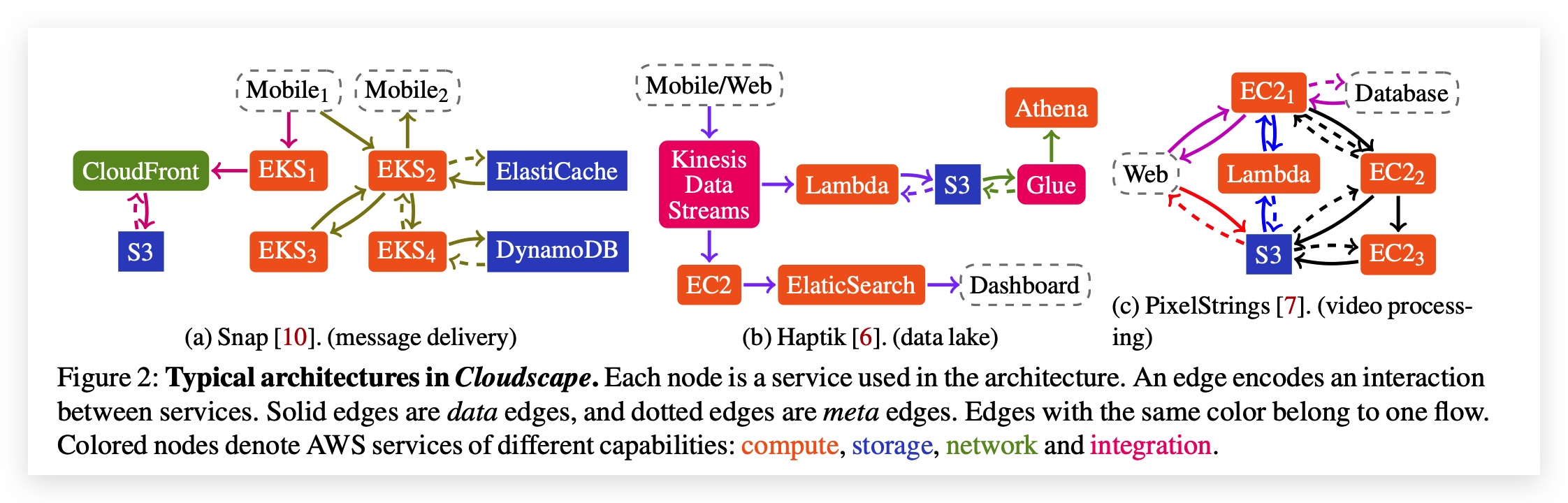
Cloudscape: A Study of Storage Services in Modern Cloud Architectures
Sambhav Satija, Chenhao Ye, Ranjitha Kosgi, Aditya Jain, Romit Kankaria, Yiwei Chen, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau
USENIX Conference on File and Storage Technologies 2025
We present Cloudscape, a dataset of nearly 400 cloud architectures deployed on AWS. We perform an in-depth analysis of the usage of storage services in cloud systems. Our findings include: S3 is the most prevalent storage service (68%), while file system services are rare (4%); heterogeneity is common in the storage layer; storage services primarily interface with Lambda and EC2, while also serving as the foundation for more specialized ML and analytics services. Our findings provide a concrete understanding of how storage services are deployed in real-world cloud architectures, and our analysis of the popularity of different services grounds existing research.
Cloudscape: A Study of Storage Services in Modern Cloud Architectures
Sambhav Satija, Chenhao Ye, Ranjitha Kosgi, Aditya Jain, Romit Kankaria, Yiwei Chen, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau
USENIX Conference on File and Storage Technologies 2025
We present Cloudscape, a dataset of nearly 400 cloud architectures deployed on AWS. We perform an in-depth analysis of the usage of storage services in cloud systems. Our findings include: S3 is the most prevalent storage service (68%), while file system services are rare (4%); heterogeneity is common in the storage layer; storage services primarily interface with Lambda and EC2, while also serving as the foundation for more specialized ML and analytics services. Our findings provide a concrete understanding of how storage services are deployed in real-world cloud architectures, and our analysis of the popularity of different services grounds existing research.